{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
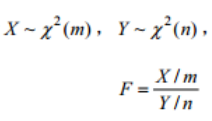{kind=link}
{kind=link}
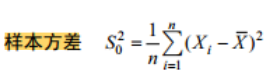{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
view-count: 3概率论与数理统计笔记
什么是统计学?
人生,是从不充分的证据开始,引出完美结论的一种艺术。——Samuel Bulter
如果我们不在同一时期,把理解了的科学知识变为我们日常生活的一部分,科学家降不可能提高他们互相拥有的知识。——J.D.Bernal
与人类有关的事实,可以由数量来表示,并且经过大量的积累重复可以导出一般规律。——英国皇家统计学会
一 事件与概率
1.1 随机试验和随机事件
-
随机现象:自然界中的客观现象,当人们观测它时,所得结果不能预先确定,而仅仅是多种可能结果之一。
-
随机试验:随机现象的实现和对它某个特征的观测。
-
基本事件:随机试验中的每个单一结果,犹如分子中的原子,在化学反应中不可再分。
e.g. 硬币抛3次,有8种结果:正正正、正正反、正反正……这8种可能结果的每一个都是基本事件。
-
随机事件:简称事件,在随机试验中我们所关心的可能出现的各种结果,它由一个或若干个基本事件组成。通常用英文大写字母表示或{一种叙述}来表示。
-
样本空间:随机试验中所有基本事件所构成的集合,通常用
e.g. 掷一枚骰子,观察出现的点数,则
-
必然事件(
-
不可能事件(
1.2 事件的运算
- 子事件

- 事件的和(

-
事件的积(

-
对立事件

- 事件

- De Morgan対偶法则及其推广
上式可推广到n个事件:
1.3 概率的定义
概率是随机事件发生可能性大小的数字表征,其值在0和1之间,即概率是事件的函数。概率有以下定义:
1.3.1 古典概率
设一个试验有N个等可能的结果,而事件
或
其中,
古典概型有两个条件:
- 有限性,试验结果只有有限个(记为n),
- 等可能性,每个基本时间发生的可能性相同。
注:古典概率可引申出“几何概率”。
1.3.2 概率的统计定义
古典概率的两个条件往往不能满足,但可以将事件的随机试验独立反复做n次(Bernouli试验),设事件
注:不能写为
,因为 不是n的函数。
1.3.3 主观概率
主观概率可以理解为一种心态或倾向性。究其根由,大抵有二:一是根据其经验和知识,二是根据其利害关系。该学派在金融和管理有大量的应用,这一学派成为Bayes学派。
1.3.4 概率的公理化定义
对概率运算规定一些简单的基本法则:
-
设
-
设
-
若事件
可推广至无穷:
注:
一般情况下,
,
1.4 古典概率计算
1.4.1 排列组合
- 选排列:从n个不同元素中取r个不同取法(
- 重复排列:从n个不同元素中可重复地取r个不同取法(
- 组合:同选排列,但不考虑次序,
注:
- 排列英文为Permutation,组合英文为Combination.
为1。当r不是非负整数时,记号 没有意义. - 一些书中将组合写成
或 ,更通用的是 .
1.4.2 其他公式
- 组合系数
- n个相异物件分成k堆,各堆物件数分为
1.5 条件概率
条件概率就是知道了一定信息下得到的随机事件的概率。设事件
为事件

注:事实上,我们所考虑的概率都是在一定条件下计算的,因为随机试验就是在一定条件下进行的。
1.5.1 条件概率性质
给定
- 若
1.5.2 乘法定理
由
注: 右边看似麻烦,其实容易算,左边看似简单,但是难算。
1.6 全概率
设
设

推导:
注:有时不易直接计算事件
的概率,但是在每个 上 的条件概率容易求出
1.7 Bayes公式
设
注:当有因果关系互换时必须用Bayes公式。
1.8 事件的独立性
设
设
上面有
注:独立(independent)和不相容(exclusive)是不同的两个概念,前者有公共部分,后者没有公共部分,独立一定相容。
1.9 重要公式与结论
二 随机变量及其分布
2.1 随机变量的概念
- 随机变量(Random variable):值随机会而定的变量,研究随机试验的一串事件。可按维数分为一维、二维至多维随机变量。按性质可分为离散型随机变量以及连续型随机变量。
- 分布(Distribution):事件之间的联系,用来计算概率。
- 示性函数(Indication function):
反 之
2.2 离散型随机变量及其分布
-
离散型随机变量:设
-
概率函数:设
-
概率分布:离散型随机变量的概率分布可以用分布表来表示:
可能值 ... ... 概率 ... ... -
概率分布函数:
- 定义:设
称为
-
性质:
是 单 调 非 降 的 : 当 - 当
-
离散型随机变量分布函数:
对于离散型随机变量,
- 定义:设
-
二项分布(Bionomial distribution):
-
定义:设某事件
称
-
服从二项分布的条件:1. 各次试验的条件是稳定的,即事件
-
-
泊松分布(Poisson distribution):
-
定义:设随机变量
则称
-
特点:
-
描述稀有事件发生概率
-
作为二项分布的近似。若
推导:
若事件
-
-
2.3 连续型随机变量及其分布
-
连续型随机变量:设
-
概率密度函数:
-
定义:设连续型随机变量
-
性质:
- 对于所有的
- 对于任意的
- 对于所有的
-
注:
- 对于任意的
- 假设有总共一个单位的质量连续地分布在
- 对于任意的
-
-
概率分布函数:设
-
正态分布(Normal distribution):
-
定义:如果一个随机变量具有概率密度函数
其中
-
性质:
- 正态分布的密度函数是以
- 若
- 正态分布的密度函数是以
-
图像(密度和分布函数图):
-


-
指数分布(Exponential distribution):
-
定义:若随机变量
其中
-
概率分布函数:
-
性质:
-
无后效性,即无老化,要来描述寿命(如元件等)的分布。
证明:
“无老化”就是说在时刻
证 : -
-
-
图像(密度函数):

-
-
均匀分布(Uniform distribution):
-
定义:设
其 它 则该分布为区间
-
概率分布函数:
-
性质:
-
2.4 多维随机变量(随机向量)
-
随机向量:设
-
离散型随机向量的分布:如果每一个
为
其具有下列性质:
注:对于高维离散型随机变量,一般不使用分布函数
-
多项式分布
-
定义:设
-
概率分布函数:
-
-
连续型随机向量的分布:
则称为
则称为
- 对任意的
-
边缘分布:因为
-
离散型随机向量

行和与列和就是边缘分布。即固定某个
-
连续型随机向量
为求某分量
-
注:二维正态分布
的边缘分布密度分别是一维正态分布 和 。因此联合分布可推边缘分布,而边缘分布不可推联合分布。
2.5 条件分布和随机变量的独立性
-
离散型随机变量的条件分布:设
为在给定
为在给定
-
连续型随机变量的条件分布:设
类似的,在
二维正态分布
-
随机变量的独立性
称随机变量
-
离散型随机变量
则联合分布律等于各自的边缘分布律的乘积,即
其中
-
连续型随机变量
则联合密度等于各自的边缘密度的乘积,即
-
更具一般地
设
则称随机变量
一些重要的结论

-
2.6 随机变量的函数的概率分布
最简单的情形,是由一维随机变量
-
离散型分布的情形:设
即把
-
连续型分布的情形
-
一个变量的情况
设
-
多个变量的情形
以两个为例,设
要求
即雅可比行列式
不为0.在
-
随机变量和的密度函数
设
- 一般的,
- 若
两个独立的正态变量的和仍服从正态分布,且有关的参数相加,其逆命题也成立。
- 一般的,
-
随机变量商的密度函数
设- 一般的,
- 若
- 一般的,
-
-
统计学三大分布
引入两个重要的特殊函数:
其中,
-
卡方分布,记作
密度函数:
性质:1. 设
2. 若
-
设
, 密度函数:
性质:密度函数关于原点对称,其图形与正态分布
-
设
密度函数:
三大分布的几个重要性质
-
设
-
设
-
设
若
-
三 随机变量的数字特征
3.1 数学期望(均值)与中位数
-
数学期望
-
定义:设随机变量
-
离散型变量的数学期望:
-
连续型变量的数学期望:
-
常见分布的数学期望:
-
泊松分布:
-
二项分布:
-
均匀分布:
-
指数分布:
-
正态分布:
-
卡方分布:
-
-
-
-
性质:
- 若干个随机变量之和的期望等于各变量的期望值和,即
- 若干个独立随机变量之积的期望等于各变量的期望之积,即
- 设随机变量
当 时 或 当 时 - 若
- 若干个随机变量之和的期望等于各变量的期望值和,即
-
-
条件数学期望
- 定义:随机变量Y的条件期望就是它在给定的某种附加条件下的数学期望。
- 性质:
- 定义:随机变量Y的条件期望就是它在给定的某种附加条件下的数学期望。
-
中位数
- 定义:设连续型随机变量
- 性质:
- 与期望值相比,中位数受特大值或特小值影响很小,而期望不然。
- 中位数可能不唯一,且在某些离散型情况下,中位数不能达到一分两半的效果。
- 定义:设连续型随机变量
3.2 方差与矩
-
方差与标准差
- 定义:设
- 常见分布的方差:
- 泊松分布:
- 二项分布:
- 正态分布:
- 指数分布:
- 均匀分布:
- 卡方分布:
- 泊松分布:
- 性质:
- 常数的方差为0,即
- 若
- 若
- 独立随机变量和的方差等于各变量方差和,即
- 定义:设
-
矩
-
定义:设
(1)
(2)
一阶原点矩就是期望,一阶中心距
-
两种重要应用:
- 偏度系数:
- 峰度系数:
- 偏度系数:
-
3.3协方差与相关系数
两者都反映了随机变量之间的关系。
-
协方差(Covariance)
- 定义:称
- 性质:
- 若
注:协方差的结果受随机变量量纲影响。
- 定义:称
-
相关系数(Correlation coefficient)
- 定义:称
- 性质:
- 若
- 若
注:相关系数常称为“线性相关系数”,实际上相关系数并不是刻画了

- 定义:称
3.4大数定理和中心极限定理
-
大数定理
“大数”的意思,就是指涉及大量数目的观察值
- 定义:设
- 定义:设
-
中心极限定理
即和的分布收敛于正态分布。
-
定义:设
-
特例:设
注:如果
其中
若把
在应用上式,则一般可提高精度。
-
四 统计量及其分布
该部分后续需拓展
4.1 总体与样本
-
总体
在一个统计问题里,研究对象的全体叫做总体,构成总体的每个成员称为个体。根据个体的数量指标数量,定义总体的维度,如每个个体只有一个数量指标,总体就是一维的,同理,个体有两个数量指标,总体就是二维的。总体就是一个分布,数量指标就是服从这个分布的随机变量。
总体根据个体数分为有限总体和无限总体,当有限总体的个体数充分大时,其可以看为无限总体。 -
样本
- 定义:
从总体中随机抽取的部分个体组成的集合称为样本,样本个数称为样本容量。
-
性质:
-
二重性:抽取前随机,是随机变量;抽取后确定,是一组数值。
-
随机性:每个个体都有同等的机会被选入样本。
-
-
独立性:每个样本的取值不影响其他样本取值,即分部独立。
满足后面两个性质称为简单随机样本,则
-
分组样本
只知样本观测值所在区间,而不知具体值的样本称为分组样本。缺点:与完全样本相比损失部分信息。优点:在样本量较大时,用分组样本既简明扼要,又能帮助人们更好地认识总体。
4.2 样本数据的整理与显示
-
经验分布函数
若将样本观测值
当 当 当 则称为

-
格里纹科定理
设
表明当n相当大时,经验分布函数
-
频数频率分布表
有样本
- 确定组数k;
- 确定每组组距,通常取每组组距相等为d(方便起见,可选为整数);
- 确定组限(下限
- 统计样本数据落入每个区间的频数,并计算频率。
该表能够简明扼要地把样本特点表示出来。不足之处是该表依赖于分组,不同的分组方式有不同的频数频率分布表。

-
直方图
- 利用频数频率分布表上的区间(横坐标)和频数(纵坐标)可作为频数直方图;
- 若把纵坐标改为频率就得频率直方图;
- 若把纵坐标改为频率/组距,就得到单位频率直方图。这时长条矩形的面积之和为1.

-
茎叶图
把样本中的每个数据分为茎与叶,把茎放于一侧,叶放于另一侧,就得到一张该样本的茎叶图。比较两个样本时,可画出背靠背的茎叶图。茎叶图保留数据中全部信息,当样本量较大,数据很分散,横跨二、三个数量级时,茎叶图并不适用。

4.3 统计量及其分布
-
统计量
不含未知参数的样本函数称为统计量。统计量的分布称为抽样分布。
-
样本均值
-
定义:
样本
样本均值是样本的位置特征,样本中大多数值位于
-
性质:
- 样本数据
- 若总体分布为
- 若总体分布未知,但其期望
-
-
样本方差与样本标准差
样本方差有两种,
样本方差是样本的散布特征,
在分组样本场合,样本方差的近似计算公式为
其中k为组数,
-
样本矩及其函数
- 样本的k阶原点矩
- 样本的k阶中心距
- 样本变异系数
- 样本的偏度
- 样本的峰度
- 样本的k阶原点矩

-
次序统计量及其分布
设
设总体- 样本第k个次序统计量
- 样本第i个与第j个次序统计量的联合密度函数为
-
样本中位数与样本分位数
设
为 奇 数 为 偶 数 样本的p分位数
不 是 整 数 是 整 数 其中[x]表示向下取整。中位数对样本的极端值有抗干扰性,或称有稳健性。
样本分位数的渐近分布:设总体的密度函数为 -
五数概括与箱线图
五数指用样本的五个次序统计量,即最小观测值,最大观测值,中位数,第一4分位数和第三4分位数。其图形为箱线图,可描述样本分布形状。


五 参数估计
统计学与概率论的区别就是归纳和演绎,前者通过样本推测总体的分布,而后者已知总体分布去研究样本。因此参数估计则是归纳的过程,参数估计有两种形式:点估计和区间估计(点估计和区间估计都是对于未知参数的估计,而点估计给出的是一个参数可能的值,区间估计给出的是参数可能在的范围)。
5.1 点估计
5.1.1 点估计的概念
点估计(Point estimation):设
5.1.2 点估计的方法
-
矩估计
定义:设总体概率函数已知,为
其中
矩估计基于大数定律(格里纹科定理),实质是用经验分布函数去替换总体分布,矩估计可以概括为:
-
用样本矩代替总体矩(可以是原点矩也可以是中心矩);
- 用样本矩的函数去替换相应的总体矩的函数。
注:矩估计可能是不唯一的,尽量使用低阶矩给出未知参数的估计 。
-
最大似然估计
定义:设总体的概率函数为
则称
注:最大似然估计基于样本观测数据,根据概率论思想进行参数估计,首先抽取一定样本,默认这些样本的出现概率是符合原始分布的,即恰好抽到这些样本是因为这些样本出现的概率极大,然后根据概率密度计算联合概率,形成似然函数,似然函数极值位置即为参数的估计值。最大似然估计的前提是已知数据的分布。
最大似然估计步骤:
- 写出似然函数;
- 对似然函数取对数,并整理;
- 求参数向量的偏导,令其为0,得到似然方程;
- 求解似然方程,其解为参数值。
-
最小均方误差估计
在样本量一定时,评价一个点估计好坏的度量指标可使用估计值
点 估 计 的 方 差 偏 差 的 平 方 其中,如果
定义:设有样本
-
最小方差无偏估计
定义:设
判断准则:设
则
-
贝叶斯估计
区别于频率学派,在统计推断中贝叶斯用到了三种信息:总体信息、样本信息和先验信息(频率学派只用了前两种),其中:
- 总体信息:总体信息即总体分布或总体所属分布族提供的信息,如,若已知总体是正态分布,则可以知道很多信息;
- 样本信息:样本信息即抽取样本所得观测值提供的信息,如,在有了样本观测值后,可以根据它知道总体的一些特征数;
- 先验信息:若把抽取样本看作做一次试验,则样本信息就是试验中得到的信息,如,在一次抽样后,这第一次的抽样就是先验信息。先验信息来源于经验和历史资料。
回顾贝叶斯公式:设
贝叶斯密度函数形式:
-
在参数
-
任一未知量
-
贝叶斯的观点,样本
-
从先验分布
-
从
此时,样本
-
因为
-
因为目的是对
其中,
所以可通过条件概率
该分布成为
Flag:感觉贝叶斯定理很有意思,今后也会学习相关的贝叶斯分析数据,敬请期待~
5.1.3 点估计的优良性准则
-
无偏性:设
则称
一个重要的结论:样本均值
- 样本均值的无偏性推导
为 - 样本方差的有偏性推导
其 中 当 时 代 入 式
-
有效性
无偏估计往往有很多种,以总体均值为例,
设
且至少有一个
-
相合性
根据格里纹科定理,随着样本量不断增大,经验分布函数逼近真实分布函数,即设
则称
定理1:设
则
定理2:若
矩估计一般都具有相合性:
- 样本均值是总体均值的相合估计;
- 样本标准差是总体标准差的相合估计;
- 样本变异系数
-
渐进正态性(MLE)
在很一般条件下,总体分布
-
充分性(UMVUE)
- 任一参数
- 若
- 考虑
- 任一参数
5.2 区间估计
5.2.1 区间估计的概念
-
双侧区间
设
其中,总体为连续分布时取等号,表示用足了置信水平。称随机区间
置信水平

-
单侧区间
设
则称
则称
5.2.2 区间估计的方法
-
枢轴量法
Step 1:设法构造一个样本和
Step 2:适当地选择两个常数c,d,使对给定的
(在离散场合,将上式等号改为
Step 3:假如能将
表明
注:满足条件的c和d有很多,最终选择的目的是希望平均长度
得到等尾置信区间。
例:设
解:三步法:
-
已知
它与参数
-
由于
-
在
-
5.2.3 一些情况下的区间估计
-
单个正态总体参数的置信区间
-
大样本置信区间:
-
两个正态总体下的置信区间
-
- 当m和n都很大时的近似置信区间:
- 一般情况下的近似置信区间:
-
-
六 假设检验
6.1 假设检验的基本思想和概念
-
基本思想
以“女士品茶”为例,对于该女士有没有品茶的能力,有两种假设:该女士没有品茶能力和该女士有品茶能力。在统计上这两个非空不相交参数集合称作统计假设,简称假设。通过样本对一个假设作出对与不对的判断,则称为该假设的一个检验。若检验结果否定该命题,则称拒绝这个假设,否则就接受(不拒绝)这个假设。
假设可分为两种:1. 参数假设检验,即已经知道数据的分布,针对总体的某个参数进行假设检验;2. 非参数假设检验,即数据分布未知,针对该分布进行假设检验。
-
假设检验的基本步骤
建立假设—>选择检验统计量,给出拒绝域形式—>选择显著性水平—>给出拒绝域—>做出判断
Step 1:建立假设
主要针对参数假设检验问题
设有来自某分布族
Step 2:选择检验统计量,给出拒绝域形式
根据样本计算统计量
注:不能用一个样本(例子)证明一个命题(假设成立),但是可以用一个样本(例子)去推翻一个命题。此外,拒绝域与接受域之间有一个模糊域,即统计量恰好符合法则,通常将模糊域归为接受域,因此接受域是复杂的。
Step 3:选择显著性水平
假设检验基于小概率事件,即小概率事件在一次试验中几乎不会发生,因此选择一个很小的概率值
拒 绝 为 真 由于向本是随机的,通常做检验时可能做出错误判断,由此引入了两个错误,分别为第一类错误和第二类错误,如下表所示。
观测数据情况 总体情况 总体情况 接受 第一类错误(拒真) 正确 拒绝 正确 犯第二类错误(取伪) 犯第一类错误概率:
拒 绝 为 真 犯第二类错误概率:
接 受 为 假 可以证明的,在一定样本量下,两类错误概率无法共同减小,但是当样本增加时,可以同时减小。
证明该问题需要引入是函数,下面将简单介绍势函数,但不对上述结论证明。
定义:设检验问题
第一类错误概率
Step 4:给出拒绝域
为了使得第一类错误的概率尽可能小,给定一个较小的
注:算拒绝域时,需基于标准正态分布。
Step 5:做出判断
通过样本计算统计量,若统计量在拒绝域中,则拒绝原假设,否则接受原假设。
-
检验的
不同置信水平
- 若
- 若
注:一般以
- 若
Author:钱小z
Email:qz_gis@163.com
Bio:GISer,Spatiotemporal data mining
GitHub:QianXzhen